Amazon Redshift is taking even larger strides in the world of data warehousing
Amazon Redshift materialised views enable you to significantly improve performance of complex queries that are frequently run as part of your extract, load and transform (ELT), business intelligence (BI) or dashboarding applications. Materialised views precompute and store the result sets of the SQL query in the view definition. Materialised views speed up data access, as the query doesn’t need to rerun the computation each time the query runs (further reducing the resource consumption).
The AWS feature describes, in detail, how the automatic query rewrite feature works as well as some scenarios where you could take advantage of this feature.
We were excited to see that materialised views can have their own distribution and sort keys, enabling optimisation joins for tables and data sets that have multiple join paths. To check out the detailed instructions and examples, soaking in new elements within optimising table scans and joins between two large tables, we highly recommend visiting the official source here.
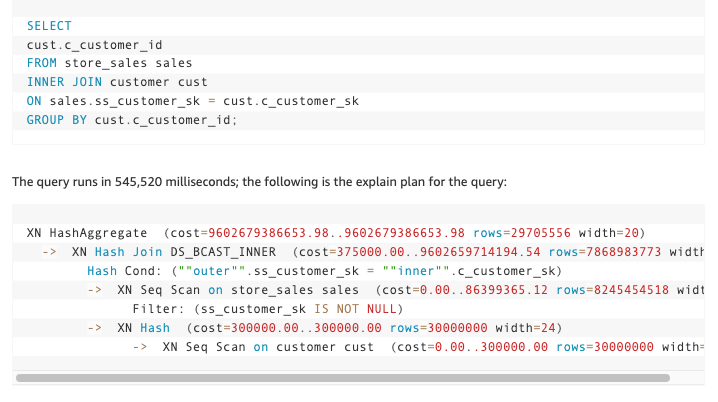
SQL statement that demonstrates the speed and compute advantages to the automatic query rewrite feature.
Setting up cross-account audit logging for your Amazon Redshift cluster
Next on the Amazon Redshift agenda are the new audit logging features, enhancements driving monitoring, security and troubleshooting. Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With Amazon Redshift, you can analyse all your data to derive holistic insights about your business and your customers. One of the best practices of modern application design is to have centralised logging. Troubleshooting application problems can be easy (when you can correlate all your data together).
When you enable audit logging, Amazon Redshift logs information about connections and user activities in the database. These logs help you monitor the database for security and troubleshooting purposes, a process called database auditing. The logs are stored in Amazon Simple Storage Service (Amazon S3) buckets and provide convenient access with data security features for users who are responsible for monitoring activities within the database.
If you want to establish a central audit logging account to capture audit logs generated by Amazon Redshift clusters located in separate AWS accounts, you can use the solution in this post to achieve cross-account audit logging for Amazon Redshift.
Jason Golding, Solutions Architect at Firemind says – “The new audit logging features within Amazon Redshift are gamechangers! As an Advanced AWS Partner, we’re continually looking for ways to improve both security within our customer solutions and enhancing troubleshooting features.”
The importance of using AWS CLI
The Amazon Redshift console only lists S3 buckets from the same account (in which the Amazon Redshift cluster is located) while enabling audit logging, so you can’t set up cross-account audit logging using the Amazon Redshift console. However, in the featured article, AWS demonstrate how to configure cross-account audit logging using the AWS Command Line Interface (AWS CLI).
There are a few prerequisites in order to follow along with the featured walkthrough, so make sure you have/can access the following:
• Two AWS accounts: one for analytics and one for centralised logging.
• A provisioned Amazon Redshift cluster in the analytics AWS account.
• An Amazon S3 bucket in the centralised logging AWS account.
• Access to the AWS CLI.